
Nov. 27, 2018
By: Michael Feldman
Amazon Web Services (AWS) has launched two new HPC cloud instances that support 100Gbps networking, as well as a network interface that supports MPI communication that can scale to tens of thousands of cores.
The first new instance, P3dn, is a variant of the original P3, which is based on NVIDIA’s V100 Tesla GPU with 16GB of HBM2 memory. P3dn uses the upgraded V100, which doubles the local memory capacity to 32GB. The 8-GPU version (p3dn.24xlarge), which is currently the only one listed, is equipped with 48 Intel Xeon Skylake processors cores (96 vCPUs) and 1.8 TB of NVMe-based SSD storage. Meanwhile, the 8-GPU P3 instance (p3.16xlarge) tops out at 32 cores Xeon (64 vCPUs). But for customers that want to scale their application beyond an 8-GPU configuration, the most critical P3dn upgrade is the addition of 100Gbps networking, which represents a 4x bandwidth boost over the 25Gbps P3 version.
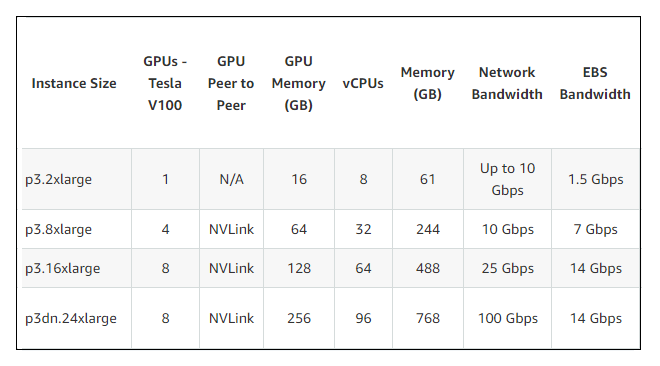
The GPU-accelerated P3 instances are broadly aimed at engineering simulations, computational finance, seismic analysis, molecular modeling, genomics, and rendering. But especially for the 8-GPU configurations, AWS is targeting customers developing machine learning models, specifically for the computationally-intensive training phase of this work. This is where the 32GB of GPU memory and 100Gbps network bandwidth in the P3dn should pay some dividends. AWS is claiming linear scalability across multiple instances for these training models, although there is undoubtably an upper limit to this assertion.
As of yet, there is no pricing for the P3dn (it won’t be available until week). The older 8-GPU P3 instance costs $24.48 per hour at on-demand pricing. Customers should expect to pay a premium for the extra goodies in the P3dn, but the additional memory and network bandwidth could end up delivering better price-performance depending on the situation. A fairly typical use case is exemplified by the AI research organization fast.ai, which spent around $40 on 16 of the original P3 instances to perform 18 minutes of Imagenet training. They’re looking to try out the P3dn to run larger models across more instances, plus reduce turnaround time.
The second new instance is the compute-intensive C5n, which improves on the vanilla C5 with more memory capacity and faster networking. Both the C5 and new C5n are powered by 3.0 GHz Intel Xeon Platinum 8000 series processors, and are offered in the same capacities, from a single core (2 vCPUs) all the way up to 36 (72 vCPUs).
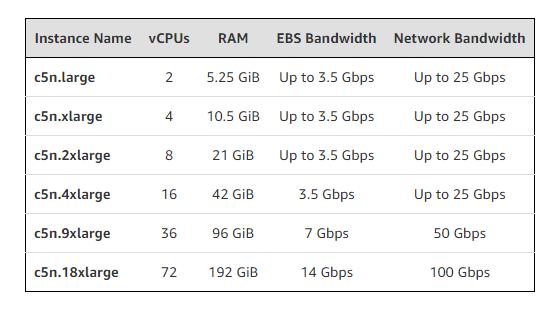
In the memory department, the C5n offers about 30 percent more per core than the C5. That works out to more than 5GB per core across the C5n portfolio. The 36-core C5n instance (c5n.18xlarge), for example, comes with 192 GiB, compared to 144 GiB in the 36-core C5 instance (c5.18xlarge). According to AWS, that put the C5n in the “sweet spot” for most HPC applications. For comparison’s sake, Japan 10-petaflop K computer offers just 2GB per core, and it has one of the better bytes/core ratios of the world’s top supercomputers.
But once again, perhaps the biggest boost in performance with the C5n will come from faster networking. The 36-core C5n instance is supplied with 100Gbps of bandwidth, four times the speed of the corresponding C5 offering. In the 18-core C5n instance, that drops down to 50Gbps, and then settles out at 25 Gbps at 8 cores and below. All these, however, represent a much-improved bandwidth compared to the corresponding C5 instances. As with the P3dn instance, the idea is to support better scalability for HPC codes, especially those that being constrained by network speeds. The higher bandwidth can also be used to speed up data transfers to and from Amazon’s Simple Storage Service (S3), which in some cases could reduce application run-time significantly.
C5n instances are aimed at high performance web serving, scientific modelling and simulations, batch processing, distributed analytics, machine/deep learning inference, ad serving, highly scalable multiplayer gaming, and video encoding. The new instances are currently available in the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), and AWS GovCloud (US-West) regions. Pricing varies according to region and use profile, but for on-demand access, the 36-core C5n instance using Linux can be had for less than $3.50 per hour in a handful of US locales.
In conjunction with the new HPC instances, AWS has also introduced something called the Elastic Fabric Adapter (EFA), a network interface that is aimed at customers that need high levels of inter-instance communication. At its core, it relies on a custom-built OS-bypass technique to speed up communication between instances. EFA provides support of applications using the Message Passing Interface (MPI) by employing the industry-standard libfabric APIs. As a result, codes using a supported MPI library can get by with little or no source modifications.
According to AWS, the EFA technology will enable customers to scale their applications to tens of thousands of CPU cores. It’s aimed at typical scalable HPC codes such as computational fluid dynamics, weather modeling, and reservoir simulation, to name a few. EFA will be available as an optional networking feature that can be enabled on selected instances. For now, it’s restricted to the C5n.9xl, C5n.18xl, and P3dn.24xl instances. More instances will be added in the coming months.
The fact that these new offerings are focused on improved networking for HPC setups should come as no surprise. Given the shortcomings of cloud network infrastructure compared to on-premise clusters and the growth of high performance workloads in the cloud – both traditional HPC and AI-related – there was latent demand to be met.
Also, with rivals like Microsoft Azure using InfiniBand in its HPC cloud infrastructure, AWS was starting to trail the competition. In fact, in September, Microsoft announced it had created new HPC VMs with 100Gbps EDR InfiniBand support. AWS has not revealed the underlying network technology for its 100Gbps hookup, but whether it’s based on InfiniBand or Ethernet, Amazon has seemingly matched Azure in raw network bandwidth.
All of this points to the increasing importance of networking capability for HPC setups, and that’s true whether you’re talking about in-house clusters or public clouds. The importance of networking is primarily result of a flagging Moore’s Law, which is failing to keep pace with HPC user demands. That forces applications to scale out further across a network rather than up across a node. Now that public clouds like AWS, Azure and others have essentially the same set of processors used in HPC clusters and supercomputers, it’s only natural that they start to mimic the high performance network of those systems.