July 18, 2016
The European Union is funding a number of HPC projects that are exploring different hardware and software technologies for exascale computing. One of these, known as DEEP-ER, expands on the notion of the “Cluster-Booster” architecture of its predecessor, the DEEP project. Using a mix of European HPC technologies from German, Italy and elsewhere, DEEP-ER is exploring some of the thornier issues of exascale, in particular, I/O scalability and system resiliency.
 The project, which began in 2013 is now its final months, and will conclude in September of this year. TOP500 News asked DEEP-ER’s project manager, Dr Estela Suarez, to talk about what has been accomplished to date, what the prototype system looks like, and what might come next.
The project, which began in 2013 is now its final months, and will conclude in September of this year. TOP500 News asked DEEP-ER’s project manager, Dr Estela Suarez, to talk about what has been accomplished to date, what the prototype system looks like, and what might come next.
TOP500 News: Let’s begin by setting the stage. What are the major objectives of the DEEP-ER project?
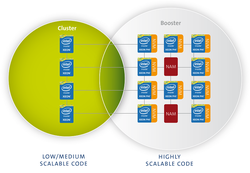
Dr. Estela Suarez: As the DEEP-ER project fundamentally builds on its predecessor project DEEP, I’ll broaden the scope of my answer to set the scene. In DEEP, we proposed an innovative approach to heterogeneous computing architectures, which we call the “Cluster-Booster architecture.” What you see in supercomputing at the moment are usually two lines of machines: massively parallel systems for applications that are very highly scalable, and commodity clusters for those problems that are not as scalable or just require a high single-thread performance.
With the Cluster-Booster approach we combine those machines into a single system. We have a classic HPC cluster built of Intel Xeon processors and attach to it a cluster of autonomous accelerators which we call the “Booster.” This approach significantly increases the flexibility in the assignment of accelerators to CPUs, what makes it interesting for a very wide range of HPC applications from classic Lattice QCD to brain simulation to climate modeling.
In this first project DEEP we have focused on proving this architectural concept by building our first prototypes and implementing a standards-based matching software stack, ensuring the machine is easy to use for application developers.
Now in the follow-up DEEP-ER project we improved our architecture from a hardware point of view, introducing a multi-level memory hierarchy. Plus, we pursued an even stronger focus on the software parts of the project, where we developed a comprehensive resiliency stack and an elaborated I/O concept for data-intensive applications.
TOP500 News: Could you go into some detail on how the Cluster-Booster architecture developed as part of the DEEP project will be enhanced in DEEP-ER?
Suarez: In a nutshell, the Cluster-Booster approach itself remains, but we implement it with newer technology, which now includes a multi-level memory hierarchy. This enables us to improve performance, especially regarding I/O.
In more concrete terms, our current prototype will also be based on the water-cooled Eurotech Aurora technology, and will also feature the second generation of Intel Xeon Phi processors (KNL). Apart from performance gains what is most interesting to us is that KNL is self-bootable. With the Knights Corner processors in DEEP we had to do some tricks to make our Booster self-bootable. This we could only do via the EXTOLL network, European technology spun out of research performed at Heidelberg University.
Also, we now have available the latest release of the EXTOLL Tourmalet ASIC for our network, which gives us significant performance gains for both, throughput and latency, as well as improved configuration and management features.
Finally, an essential enhancement with respect to DEEP is the DEEP-ER multi-level memory hierarchy, which leverages new technologies in this field.
TOP500 News: What types of new memory technologies are being explored and how are they being used?
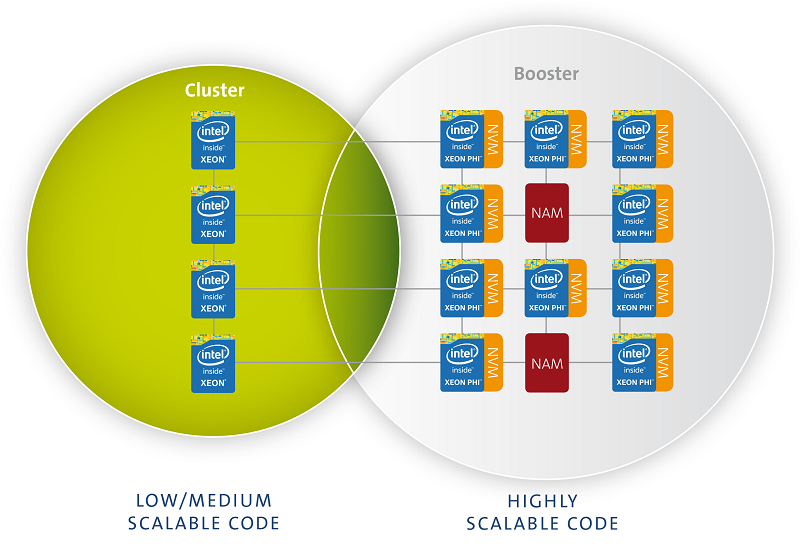
Suarez: We use non-volatile memory devices (NVM) based on the NVMe standard and additionally develop network attached memory (NAM) prototypes. Generally speaking, we see that many applications increasingly suffer from the diverging growth rates of processor compute performance -- fast, driven by multi/manycore -- and bandwidth to storage that improves only slowly. To cure this imbalance, we add additional levels to the memory and storage hierarchy with NVM and NAM. We follow a strong co-design process between hardware, software and application developers in order to guarantee, these technologies fit with our overall resiliency and I/O concepts and to make sure they are easy to use for our DEEP-ER users.
In more detail, we believe that NVM will play an important role for parallel I/O in general and for the checkpoint/restart functionality necessary for a resilient operation of Exascale systems. Both areas (I/O and resiliency) can profit from having large memory pools available close to the nodes to reliably store data for later processing or asynchronous migration to permanent storage devices with limited bandwidth. With respect to the prototype, all nodes, both Xeon nodes in the Cluster and Xeon Phi nodes in the Booster, will possess one NVMe device each. Our NVM experts and our application developers have already run various benchmarks and tests that look quite promising.
The NAM is a more exploratory field of research. However, we think it provides very interesting perspectives for HPC and hence we are very eager to test it. We have built a prototype coupling a Hybrid Memory Cube (HMC) to a powerful FPGA, which both controls the HMC and speaks to the network. The NAM prototype available to the project is currently fully verified and the team works on first use cases, which were identified together with the application developers in the team. The most promising and interesting one to start with is exploiting the NAM as an additional resiliency feature and use it for writing parity checkpoints.
TOP500 News: Could you describe the Xeon Phi-based prototype being developed?
Suarez: As in DEEP, the DEEP-ER prototype will include a Cluster and a Booster side, which will be tightly connected to each other via the EXTOLL network. The Cluster part has been already deployed and contains 16 Haswell generation Intel Xeon processors connected by a EXTOLL Tourmalet torus network. The Booster side, planned to be deployed in autumn this year, will be a water-cooled Eurotech Aurora Blade system.
Each Aurora chassis will be populated with 18 Intel Xeon Phi KNL processors, 18 Intel DC P3400 NVMe devices, and 18 EXTOLL Tourmalet NICs, with a one-to-one assignment of the three kinds of components, all of which will be connected to each other through a PCIe Gen3 backplane.
We are thinking about building a Booster of 54 or 72 KNL nodes. The exact size will be determined according to component pricing and budget available. So overall, the DEEP-ER prototype will be smaller than the DEEP one, which we’ll continue using for scalability tests.
You might wonder why we are building a new system at all instead of updating the existing DEEP one. Well, the DEEP project built indeed a pretty large Cluster-Booster prototype, with the Booster based on Intel KNC-generation Xeon Phi processors and an FPGA implementation of the EXTOLL network, both of which we need to update now to the newly available versions of the same technologies – KNL and the EXTOLL Tourmalet ASIC, respectively.
The DEEP Booster was a very tightly integrated system, since we wanted to achieve the highest possible density and energy efficiency. This is great, but the negative consequence of this is that it is not possible to just exchange the KNC boards by KNL boards, and the FGPAs by EXTOLL ASICs, keeping the rest of the system as it is. A redesign of the whole was needed, including complete new Aurora blades, a new backplane, and even a new chassis design. So, deploying a full new prototype for DEEP-ER was the only way we could go for getting the latest technology.
TOP500 News: Can you give us an overview of the I/O system being envisioned and the requirement that drove the design decisions?
Suarez: As you can imagine our overall goal is to reduce the time spent on I/O processing to maximize time spent on actual compute operations. With this vision in mind, we have come up with an I/O stack that is based on three closely integrated components: the parallel file system BeeGFS, the parallel I/O library SIONlib and E10 middleware for collective I/O processes. These components represent the different approaches to improve the efficiency of I/O on the way towards exascale.
BeeGFS as a file-system aims at improving I/O by means of relaxing some of the requirements postulated by the POSIX standard. SIONlib's approach is to merge task-local I/O into operations acting on few files on the parallel file system. Last but not least, the E10 approach is to enable applications utilizing MPI-IO to benefit from the mechanism provided by the two other components.
The key idea behind this complex setup is to enable the project to determine the efficiency of each of the single approaches and the possible interplay between them, using our applications as the yardstick. The final goal of DEEP-ER's efforts in this area is to attain an insight into the additional effort that needs to be invested to reach exascale-capable I/O middleware.
Generally speaking, this I/O stack allows for a lot of flexibility. What we currently see as the most common scenario is that applications use SIONlib for task-local I/O or E10 for collective MPI-I/O based on, for example, parallel HDF5. BeeGFS then acts as the compound layer between SIONlib or E10 and the hardware architecture to ensure seamless and effective communication between the applications and the underlying hardware, such as NVMe devices.

TOP500 News: Can you talk about why you chose Fraunhofer’s BeeGFS as the file system underlying the I/O system you are developing, as opposed to existing parallel file systems like Lustre or GPFS?
Suarez: There are two lines of arguments to this. The first is more strategic, let’s say. It’s a European technology and both sides – the consortium and BeeGFS – were interested in collaborating. That makes it a lot easier to realize new ideas and also to explore more experimental features.
But obviously there were also strong technical reasons for going with BeeGFS. For instance, the way BeeGFS handles metadata is pretty interesting. It is very likely that it will scale much better for metadata operations than other solutions. Plus, the concept for cache-domains is very attractive. I don’t want to go into too much detail, but in some cases it dismisses the strong POSIX requirements in a very controlled manner, which brings tremendous improvements in performance. Testing this and integrating it into layers above the file system looks very promising for future scalable I/O concepts.
TOP500 News: What kinds of development will be done with OmpSs in the DEEP-ER project?
Suarez: OmpSs plays an important role in our DEEP-ER resiliency concept. So the overall aim of our set of resiliency tools is to isolate soft or partial system failures and by doing so we try to avoid full application restarts. Now, depending on the type of error, be they uncorrected errors or uncorrected recoverable errors, our resiliency layers, especially the different extensions to OmpSs, apply.
One example: In both DEEP and DEEP-ER we use OmpSs for offloading large tasks, which include internal MPI communication, to either the Cluster or the Booster. OmpSs, together with ParaStation MPI, has now been enhanced in such a way, that when you encounter an uncorrected error in the offloaded part of the program, the OmpSs runtime is able to re-execute this failed tasks on the remaining nodes – without having to kill any of the processes forming the main program which initiates the offloading. By this means we are able to implement an efficient and transparent resiliency mechanism without the need of introducing explicit checkpoint / restart calls into the application program.
TOP500 News: How do you foresee the results of DEEP-ER being used?
Suarez: For one, we make available our DEEP and DEEP-ER prototypes to application developers outside of the project. The idea is to educate users on this new type of architecture and let them play with it. Eventually, Eurotech plans to productize the DEEP-ER prototype after the project's end.
With DEEP this did not make too much sense as the technology based on KNC is about to be outdated.
Jülich Supercomputing Centre also plans to expand its JURECA system by a Booster of 10 petaflops in the midterm, also at production level obviously.
And finally, we have also plans to do further research and development and extend the Cluster-Booster concept to something we like to call Modular Supercomputing. The idea is to integrate, for example, a module for data analytics for the upcoming big data applications in HPC, just to name one of the technologically possible and interesting options.
Regarding the software, both the ParaStation and OmpSs extensions developed during the two projects will be made available through the official releases of both software products. All of them have been implemented generically, so that they can be used in other kinds of heterogeneous systems, not only on the DEEP platform. This means that with this DEEP software, we are providing to all users an advanced programming environment for future kinds of heterogeneous HPC clusters. The idea is to make life easier by sticking to standards as much as possible, and hiding the hardware complexity from the users.
And last but not least, we made remarkable progress through the code modernization efforts in all the eleven applications that participated in the projects. These include research fields such as neuroscience, astrophysics, engineering, lattice QCD, and climate research.
The flexibility given by the DEEP platform enabled the code developers to think out of the box and come up with new ideas on future directions of development concerning their applications, from new code partitions to better approaches to data locality, and even to integration of further components of their workflow into the main application. Since all the application improvements and modifications have been done with general system design in mind, the codes are now in a much better position to efficiently run on any existing and upcoming HPC system, bringing new scientific and industrial opportunities to their communities.