July 2, 2018
By: Michael Feldman
Researchers at the Great Western 4 (GW4) Alliance have benchmarked the Cavium ThunderX2 processor that will soon power the Isambard supercomputer. But the most significant advantage of the Arm processor may have nothing to do with performance numbers.
GW4, which represents four universities in the South West of England and Wales (Bath, Bristol, Cardiff Exeter), will soon be installing Isambard, a 10,000-core machine that the alliance is calling the “world’s first production Arm supercomputer.” When it comes online, it will be the most powerful Arm-powered supercomputer in the UK and second only to the Astra system scheduled to be deployed at Sandia National Laboratories later this summer.
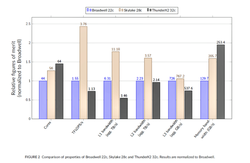
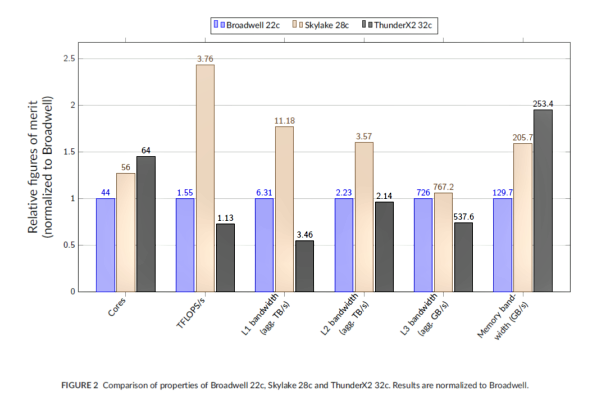
GW4 has been benchmarking pre-production versions of the ThunderX2 for at least a year, but with the ThunderX2 chips now in production, more practical comparisons can now be made with the Intel Xeon processors already in the field. In this case, a 32-core ThunderX2 was compared against a 22-core “Broadwell” Xeon and a 28-core “Skylake” Xeon. The University of Bristol’s Simon Mcintosh-Smith summarized the results in a recent blog post, which focused on floating point performance, as well as memory and cache bandwidth. The benchmark scores, illustrated below, were based on heavily used HPC codes that are run on ARCHER, the UK’s national supercomputer.
 Source: Simon Mcintosh-Smith, University of Bristol
Source: Simon Mcintosh-Smith, University of Bristol
If you’ve been following our coverage of ThunderX2 and Arm, the results are pretty much as expected. The floating-point-heavy Xeon processors were substantially better in the flops department than the ThunderX2. This is especially true for the Skylake Xeon, which incorporates 512-bit Advance Vector Extensions (AVX). By contrast, ThunderX2’s vector width is a measly 128 bits.
On the other hand, thanks to Cavium’s 8-channel memory design, the ThunderX2 has about 23 percent more memory bandwidth than the Skylake Xeon and about 95 percent more than the Broadwell chip. The cache performance results were somewhat mixed, although the Skylake Xeon came out on top across all three cache levels.
The obvious conclusion is that the Xeons are preferable for floating point-intensive codes, while the ThunderX2 are the better choice for applications that are memory bound and less reliant on floating point performance. For codes that can perform the majority of their work out of cache, the Xeon would also be the chip of choice.
One advantage the Cavium processors have is lower price. Mcintosh-Smith says Arm-based processors are “significantly cheaper than those shipping from the incumbent vendors, by a factor of 2-3X, depending on which SKUs you compare.” As a consequence, from a price-performance perspective, the flops-lite ThunderX2 could look a lot more attractive.
Mcintosh-Smith also makes the point that having a diverse set of architectures from which to choose is a good thing, independent of any specific performance advantages one particular chip may have over another. “For users, this means that we have a new set of processor vendors becoming relevant, giving us much more choice today than at any point in the last decade,” he writes.
One might be tempted ask, why can’t we have lots of flops, cache performance, and memory bandwidth on the same die? Unfortunately, with a limited amount of transistor real estate, chip designers are forced to make trade-off and hope the selected capabilities deliver the right balance for the largest number of applications.
In a way, this is easier to navigate for upstarts like Cavium, who just need to find a way to edge out the competition in one or two areas in order to grab some initial market share, rather than having to worry about a legacy customer base and the all the applications that go with them. It’s interesting that AMD, with a similar mandate to snatch some of Intel’s market share with its EPYC processor, also focused on memory performance rather than big fat vectors.
Of course, despite all the talk in HPC circles these days of analytics, AI, and other data-intensive applications, the bread and butter of high performance computing is still floating point. Which suggests that for the HPC space, either the Arm community needs to start forging tighter alliances with accelerator providers like NVIDIA, AMD, and Xilinx, or find ways to spread its home-grown acceleration technology, such as the ARMv8-A SVE (Scalable Vector Extension) architecture. The SVE design is getting its first test in Japan, where Fujitsu is developing an implementation for RIKEN’s Post-K supercomputer. That system is expected to debut in 2021.
Along similar lines, Mcintosh-Smith also points to what he believes is Arm’s biggest advantage, namely that the licensing of its shrink-wrapped IP enables people to build customized processors at lower cost than would be possible with a commodity chip business model. The implication is that some enterprising startup or startups could construct specialized Arm processors for the HPC market, incorporating custom circuitry for vector processing, AI, or other interesting types of acceleration.
“These processors will be highly differentiated from high-volume mainstream datacenter parts, and should bring significant steps forward in performance for scientists around the world who have become increasingly frustrated with the relatively small improvements in performance and performance per dollar we’ve seen in recent years,” writes Mcintosh-Smith. “As such, Arm’s entry into the HPC market, and the injection of new ideas, innovation and competition this brings, could trigger a revolution in scientific computing of the kind not seen since the commodity CPU revolution of the late 1990’s. Exciting times are ahead.”
We’ll see.