
May 24, 2017
By: Michael Feldman
At Microsoft’s recent Build conference, Azure CTO Mark Russinovich presented a future that would significantly expand the role of FPGAs in their cloud platform. Some of these plans could sideline the use of GPUs and CPUs used for deep learning from the likes of NVIDIA, Intel, and other chipmakers.
As we reported back in September, Microsoft has deployed Altera FPGAs in every server in its Azure cloud, effectively creating an AI supercomputer. When they revealed the scope of this deployment at the Ignite Conference last year, the company demonstrated that those FPGAs could be called upon to deliver an exa-ops worth of inferencing on deep neural networks (DNNs) they use to support their cognitive computing services. Microsoft now claims it has multiple exa-ops of capacity in Azure.
Since 2015, Microsoft has been using this capability to deliver a variety of cognitive computing services in applications like Skype, Cortana, and Bing. This includes areas like language translation, speech recognition, and computer vision, just to name a few. The company also uses the FPGAs to build Bing’s search index rankings, as well as to accelerate Azure’s cloud network.

Source: Microsoft
Microsoft’s rationale for all this is that in terms of performance, flexibility, and scalability, FPGAs occupy a sweet spot between traditional processors, like CPUs and GPUs, and custom-built ASICs. While FPGAs are admittedly harder to program than traditional processors, for hyperscale purposes, the added effort seems to be worth the extra cost. For inferencing, Microsoft is seeing up to a 150 to 200-fold improvement in data throughput and up to a 50-fold improvement in energy efficiency compared to a CPU. Latency is also lowered by about 75 percent. As far as ASICs go, Microsoft has determined that they’re not a viable option, since Azure’s diverse workloads requires a more flexible computing platform.
What Russinovich revealed at Build conference was that Microsoft was looking at ways to turn Azure’s FPGA capability outward so that cloud customers could use these devices. According to him, the mantra here is “first party equals third party,” which describes the process in which technologies that are initially used internally are subsequently productized for external use, in this case via the cloud. One of the prime use cases would be deep learning inferencing, with Azure customers bringing their own neural network models with them. Russinovich did not say when this service would become available, offering just “sometime in the future.”
Russinovich also said they are working on moving the more computationally intense training of the neural networks over to FPGAs. He didn’t talk about this at length since it appears the company is in the early stages of that effort. There also might be some sensitivity to its partners, particularly NVIDIA, whose GPUs it currently relies on for training its own neural networks, as well offering them to cloud customers. In fact, while the Build conference was taking place, Microsoft’s corporate VP for Azure, Jason Zander, was at the GPU Technology Conference cheering on NVIDIA and its Volta GPU launch.
Microsoft’s relationship with Intel in this area is even trickier. Azure currently uses Altera/Intel FPGAs for inferencing and other applications not related to deep learning, which are use cases Intel promotes as well. But adding training into the mix means Microsoft is much less likely to pick up Intel’s future Nervana-flavored deep learning products.
Intel also must consider that Microsoft might switch horses at some point and start buying Xilinx FPGAs for their reconfigurable computing needs. For the time being, this is not a concern since the next iteration of Azure servers will be based on the Project Olympus design, which will use Altera’s Arria 10 FPGAs. But future servers are certainly up for grabs, given that Microsoft doesn’t play favorites with chip companies. Project Olympus currently supports silicon from Intel/Altera, NVIDIA, AMD, Qualcomm and Cavium.
Bringing training onto the FPGAs will be facilitated by a technology Microsoft refers to as “hardware microservices.” Essentially, it’s a generalized software framework for FPGAs that enables them to be used as a virtual cloud resource, decoupling them from their CPU hosts. The key to this is that the FPGAs are hooked directly into the network, allowing them to be fed with work independently from their hosts. One consequence of this is that the CPU-to-FPGA ratio on any given application can be whatever you want, that is, it can be based on workload need rather than the server hardware configuration.
Source: Microsoft
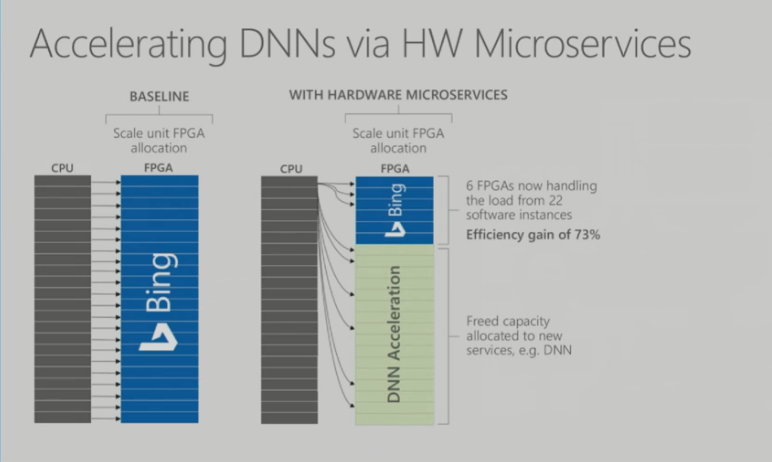
For deep neural networks, they are able to distribute the layers of the trained network across FPGAs and then weighting the layers via the network communication. According to Russinovich, they already are using this in Bing to accelerated the deep learning associated with that application “So now we’ve got massively scalable DNNs, independently scaling from the CPUs, where the deep neural network is basically laid out across this fabric of FPGAs,” explained Russinovich.
One huge advantage with the microservice model is that Microsoft is able to get better utilization out of the FPGAs. In the example Russinovich described, they were able to pack 6 FPGAs with neural net processing from 22 software threads on the CPUs, realizing a 73 percent efficiency gain. The unused FPGAs can be used for other workloads, he said, noting that “our cognitive services are being trained on those FPGAs now.”
Microsoft wants to generalize this model across all their FPGA-friendly workloads – deep learning, SQL acceleration, network acceleration, search, and others. In essence, they are looking to creating a general-purpose reconfigurable layer in Azure, which can be resourced dynamically as needs arise. Again, Russinovich declined to offer a timeline on this, only saying that they are actively working on putting this into production for internal needs.
Once Microsoft has these microservices in production, it’s a small leap to offer this capability to Azure customers. At that point, they will have something similar to what Google is offering with its new Tensor Processing Units (TPUs), namely a massive AI cloud that can be used both internally for its own deep learning services, and externally for third parties. Except with FPGAs and microservices, Microsoft has a more general-purpose platform, which could conceivably be exploited for a variety of workloads – database acceleration, graph analytics, and even traditional high performance computing.
For the time being, other big hyperscale companies like Amazon, Facebook, IBM, Baidu, and Alibaba are sticking with CPUs and GPUs. But with Google and Microsoft now moving to more specialized componentry, this might spur their competitors to differentiate as well, with chipmakers, large and small, vying for position. Any way you look at, it’s going to be an interesting ride.