
June 27, 2017
By: Michael Feldman
Even though there wasn’t much turnover in the latest TOP500 list, a number of new petascale supercomputers appeared that reflect a number of interesting trends in the way HPC architectures are evolving. For the purposes of this discussion, we’ll focus on three of these new systems: Stampede2, TSUBAME 3.0, and MareNostrum 4.
First let’s dispense with the notion that these supercomputers are mere sequels to their previous namesakes. What they really have in common is their architectural diversity and their use of the very latest componentry. It’s notable that none of these three systems have been completed yet since they rely on hardware that is not yet generally available or could not be procured in the quantities needed in 2017.
 Stampede2, the NSF-funded system at the Texas Advanced Computing Center (TACC), is currently the most powerful of the trio, at least by Linpack standards. Its 6.8-petaflop run was enough to earn it the number 12 slot on the TOP500 list. TACC director Dan Stanzione admitted to us at TOP500 News that they probably could have moved up a notch or two in the rankings if they had worked a bit harder on extracting more Linpack flops from the system’s 12.8 peak petaflops.
Stampede2, the NSF-funded system at the Texas Advanced Computing Center (TACC), is currently the most powerful of the trio, at least by Linpack standards. Its 6.8-petaflop run was enough to earn it the number 12 slot on the TOP500 list. TACC director Dan Stanzione admitted to us at TOP500 News that they probably could have moved up a notch or two in the rankings if they had worked a bit harder on extracting more Linpack flops from the system’s 12.8 peak petaflops.
Nevertheless, the Stampede2 is currently the most powerful supercomputer Xeon Phi-based supercomputer in the US. The system is comprised of 4,200 nodes, each equipped with a 68-core Knights Landing processor along with 16GB of 3D high-speed MCDRAM and 96 GB of conventional DDR RAM. The nodes are hooked together using Intel’s Omni-Path fabric, running at 100 Gbps. Stampede2 was built and installed by Dell, with Seagate supplying the storage, in this case, two Lustre file systems, providing 32 petabytes of capacity.
This fall, Stampede2 will add 1,736 Skylake Xeon nodes, which Stanzione estimated would add another two to three petaflops. Intel is expected to officially launch these processors next month, when they should become more widely available (three TOP500 systems already have Skylake Xeons installed, including MareNostrum 4).
The rationale for the added multicore Xeons is to offer TACC users a more conventional platform for applications and one in which faster single-threaded performance is provided. The manycore Xeon Phi chips offer lots of parallelism, but with fairly modest thread performance, due to the slower clock frequencies – 1.4 GHz in the case of the chips installed in Stampede2. While the standalone Knights Landing Xeon Phi solves the processor/coprocessor ineffciencies, it still suffers from the compromise of slower cores.
In 2018, TACC will install Intel’s high-capacity 3D XPoint DIMMs into 50 to 100 of the Skylake servers, the idea being to create some fat nodes in the system for in-memory computing and other data-demanding codes. Its non-volatile nature is an additional feature that some HPC codes may be able to take advantage of. Intel is expected to release the 3D XPoint DIMMs, under its Optane brand, sometime next year.
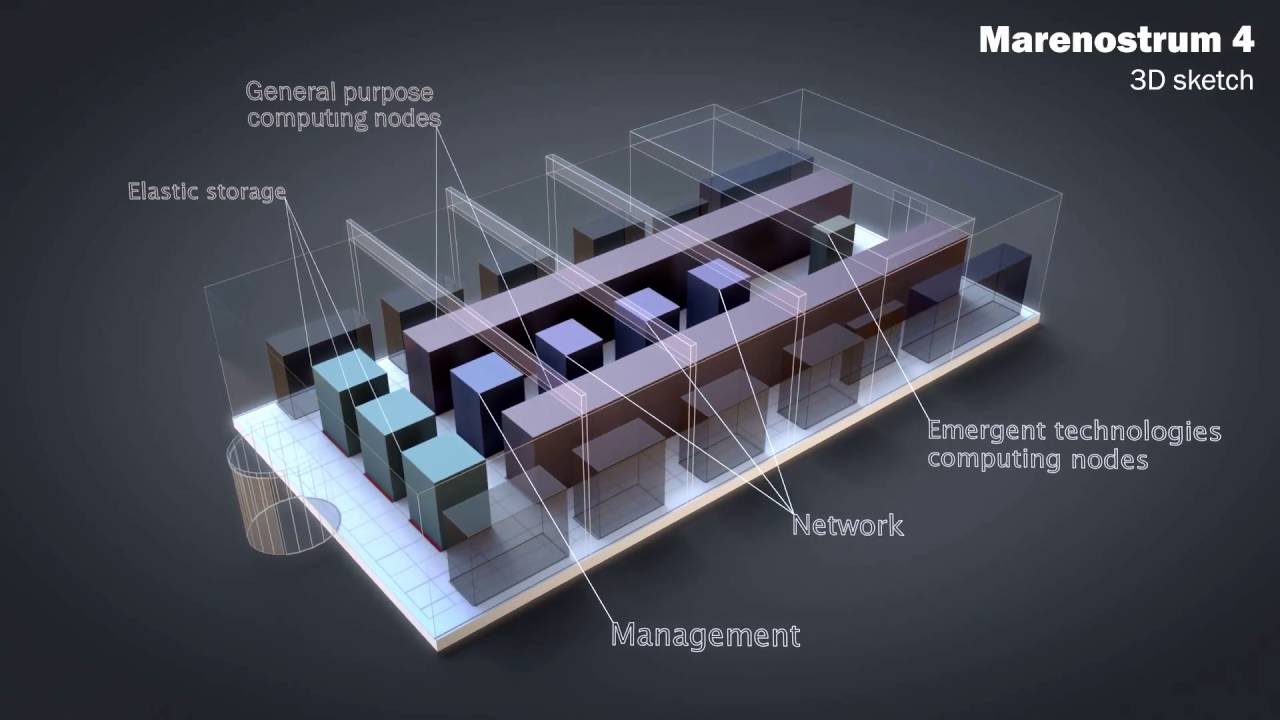 Not everyone was stuck waiting in line for pre-launch Skylake Xeons. The Barcelona Supercomputing Center (BSC) and Lenovo managed to get hold of more than 6,000 of them to construct the main cluster of the new MareNostrum 4 machine. Specifically, the system is equipped with the new Xeon Platinum 8160 processors, a 24-core chip running at 2.1 GHz. With more than 3,400 nodes of the new chips, MareNostrum 4 achieved a Linpack mark of 6.2 petaflops, capturing the number 13 spot on the June TOP500. Like its counterpart in Texas, it also uses Omni-Path as the system interconnect.
Not everyone was stuck waiting in line for pre-launch Skylake Xeons. The Barcelona Supercomputing Center (BSC) and Lenovo managed to get hold of more than 6,000 of them to construct the main cluster of the new MareNostrum 4 machine. Specifically, the system is equipped with the new Xeon Platinum 8160 processors, a 24-core chip running at 2.1 GHz. With more than 3,400 nodes of the new chips, MareNostrum 4 achieved a Linpack mark of 6.2 petaflops, capturing the number 13 spot on the June TOP500. Like its counterpart in Texas, it also uses Omni-Path as the system interconnect.
Also like Stampede2, MareNostrum 4 is a work in progress. The second phase of the system will add three sub-clusters, each based on different processors. One will be an IBM Power9/NVIDIA V100 GPU cluster, using the same chip combo as in the US Department of Energy’s upcoming Summit and Sierra supercomputers. The second cluster will be powered by Intel Xeon Phi processors, in this case, a combination of the current Knights Landing and the future Knights Hill processors. The third cluster will be supplied by Fujitsu using the same architectural elements as in its upcoming Post-K exascale system. Presumably this means Fujitsu’s vector-enhanced ARM implementation of the ARMv8-A SVE architecture, along with the company’s Tofu interconnect.
The rationale for this rather eclectic mix of processors is to expose BSC’s user base to technology that may be the basis for future iterations of MareNostrum. More than any system discussed here, MareNostrum 4 reflects the uncertainty (and the opportunities) surrounding future supercomputer architectures.
Of the three supercomputers mentioned here, TSUBAME 3.0 at Tokyo Tech is the one without an identify crisis, at least with regard to its hardware. As with past iterations of TSUBAME, it relies on GPU acceleration to deliver the majority of the flops, with the Intel Xeon processors in a support role. In this third-generation version, it’s the NVIDIA P100s doing the heavy lifting. The current installation, which is based on the HPE SGI 8600 platform, offers 3.2 peak petaflops and 1.9 Linpack petaflops, enough to be ranked as the 61st most powerful supercomputer in the world. When all 2,000-plus P100 are installed later this year, the system is expected to achieve 12.2 peak petaflops.
 Where it veers from previous versions of TSUBAME is that it uses more GPUs per node – four in this case – and adds four 100 Gbps Omni-Path interfaces to provide extra bandwidth between nodes. There are also two PCIe switches per node to maximize communication between the CPUs, GPUs, and Omni-Path fabric. The goal here is to ensure that inter-node and inter-processor and bottlenecks are kept to a minimum. (The GPU cross-talk bottleneck is solved with the NVIDIA’s native NVLink interconnect.) Each node also is equipped with a 2 TB NVMe SSD to accelerate I/O.
Where it veers from previous versions of TSUBAME is that it uses more GPUs per node – four in this case – and adds four 100 Gbps Omni-Path interfaces to provide extra bandwidth between nodes. There are also two PCIe switches per node to maximize communication between the CPUs, GPUs, and Omni-Path fabric. The goal here is to ensure that inter-node and inter-processor and bottlenecks are kept to a minimum. (The GPU cross-talk bottleneck is solved with the NVIDIA’s native NVLink interconnect.) Each node also is equipped with a 2 TB NVMe SSD to accelerate I/O.
The bigger change is on the application side. The TSUBAME 3.0 design reflects Tokyo Tech’s desire to run more big data codes, in general, and more deep learning codes, specifically. The combination of the deep-learning-optimized P100 GPUs and the abundant inter-node and inter-processor bandwidth is geared for such applications. While it will certainly be running plenty of traditional HPC simulation workloads, TSUBAME 3.0 looks like it’s going to be one of Japan’s major testbeds for running deep learning applications at scale.
Given the additional hardware needed to deliver the extra bandwidth, it’s notable that TSUBAME 3.0 is also the current Green500 champ. It achieved an impressive 14.1 gigaflops per watt running Linpack, which is nearly 50 percent better than NVIDIA’s P100-powered DGX SATURNV system that topped the list just six months ago. The Tokyo Tech benchmarkers achieved this feat by reducing performance to a modest degree, which yielded much better energy efficiency. Such a tradeoff is very likely to be used in future supercomputing systems to keep power costs in line.
It remains to be seen which of these architectures remains commercially viable over the next decade. Perhaps all of them will, which means it will fall to application developers to create portable codes across many platforms. Or it may end up creating architectural silos for different applications. Such may be the price of performance in the exascale era.