Sept. 16, 2016
By: Michael Feldman
In these days of Apple Siri, Amazon Alexa, and Google Now, AI-based speech generation has become a commonplace technology in everyday life. But when machines talk to us, it’s still obvious that we are listening to a computer, and not a human voice. Thanks to new machine learning technology from Alphabet's DeepMind, that may soon change.
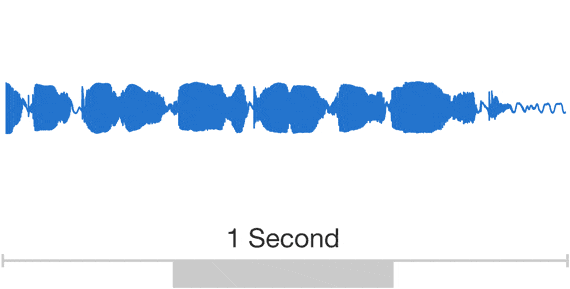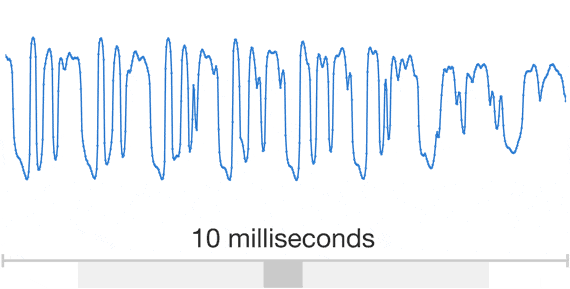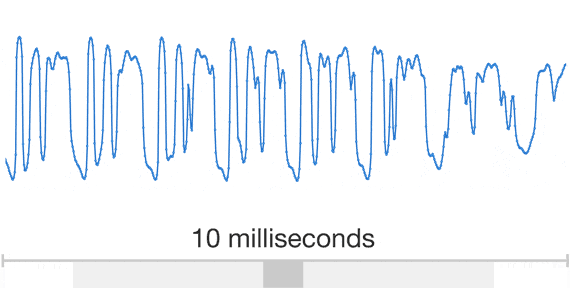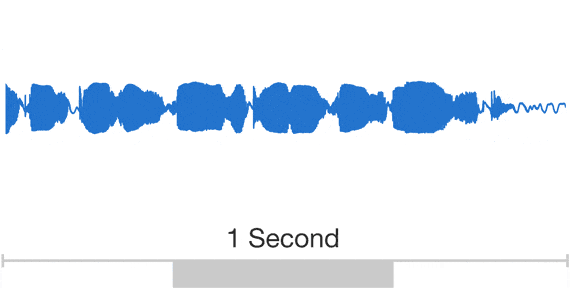
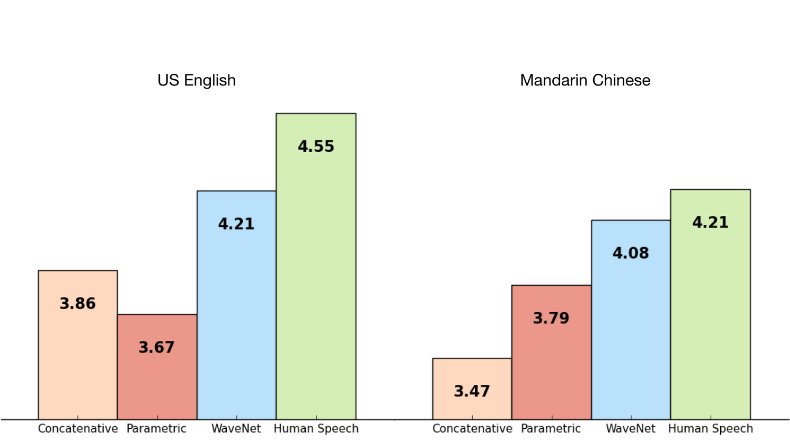
DeepMind has developed something called WaveNet, a deep neural network application that is able to generate speech that sounds more natural than the robotic-sounding voices we experience in current consumer products. In fact, the new technology is said to reduce the gap between state-of-the art computer-generated speech and human speech by more than 50 percent. It is able to do this using a new approach that synthesizes speech based on raw audio waveforms, in this case, actual recordings of people speaking.
 Source: deepmind.com
Source: deepmind.com
Speech generation developers have generally avoided using raw audio since it is extremely data-intensive to process. Decent audio is recorded at 16,000 samples per second or more. Training a predictive model based on that level of intensity is challenging, to say the least. But the DeepMind developers figured out a way to build a model from these waveforms using a convolutional neural network. According to the WaveNet description, the process works as follows:
At training time, the input sequences are real waveforms recorded from human speakers. After training, we can sample the network to generate synthetic utterances. At each step during sampling a value is drawn from the probability distribution computed by the network. This value is then fed back into the input and a new prediction for the next step is made. Building up samples one step at a time like this is computationally expensive, but we have found it essential for generating complex, realistic-sounding audio.
By training the network on audio of actual recordings of human speech, the result is less mechanical sounding than the two other most common speech synthesis models: concatenative and parametric. If you scroll down toward the bottom of the WaveNet web page, you can listen to some text-to-speech (TTS) audio of all three approaches. The WaveNet version is still not quite human, but there is a noticeable improvement from the two other models.
 Source: deepmind.com
Source: deepmind.com
Interestingly, the DeepMind developers found that when they trained the network to learn the characteristics of different voices, both male and female, it became better at modeling a single speaker. That suggested that “transfer learning” was taking place, something they had not anticipated. Perhaps even more surprising, is that when they changed the audio input to classical piano recording, WaveNet was able to generate respectable musical sequences, without any direction on the types of arrangements desired. You can listen to some examples below the TTS discussion.
In the description of the WaveNet technology, the researchers didn’t specify the underlying hardware that was needed to perform the processing. There were some online reports that it took 90 minutes of processing on a GPU-accelerated cluster to generate one second of audio, but that information was based on a now-deleted tweet from a DeepMind researcher. It’s certainly plausible that you would need a decent-sized deep learning cluster to do the inference part of this work, given the computational demands of synthesizing speech from such a model. Nevertheless, the results here are so promising and the application scope so wide, that further advances in software, not to mention hardware, are almost assured.